深度学习
22 Nov 2019人工智能
智能本身的定义是很模糊,图灵测试给出了一个实际判定人工智能的方法,但这个方法本身也存疑,有点哲学化了。
机器学习本质上也是一个算法,但和传统算法完全不一样,传统的计算机算法,是有了输入,通过设计好的算法,产生输出,但很多现实问题很复杂,没办法写出算法,但是可以有一些例子(经验数据),机器学习就是在经验数据上推导出算法的算法,再用推导出的算法就求解新的输入数据。机器学习算法的严谨定义就是:基于经验随时间不断改善性能。
深度学习
深度学习的技术很早就有,以前叫做多层感知机。随着BP算法和GPU加速大大提高深度网络的训练效率,近年逐渐热起来,神经网络很擅长处理输入为语音、图像、视频类的场景,并且逐渐扩展到很多领域,比如游戏、视觉生成等, NLP(自然语言处理)。
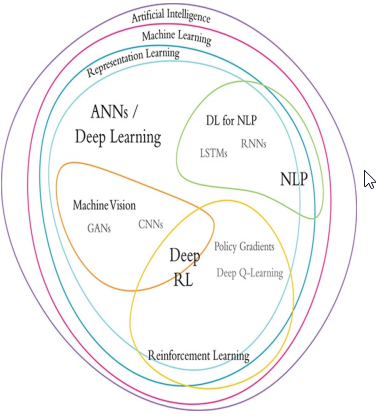
“深度”通常是指多层的神经网络,具体几层算深度,并没有明确定义,看一下深度学习的发展历史和典型的应用:
- 1950 MLP多层感知机诞生,其实就是现代深度神经网络的原型,在80年代曾经很流行。
- 1998 LENET 第一个CNN模型,提出很多影响后世的思想,只是因为当时算力不够,此后深度学习陷入低潮。
- 2012 AlexNet 8层 ImageNet错误率16.4% - 重新开启深度学习大潮
- 2014 VGG 19层 ImageNet错误率7.3%
- 2015 ResidualNet 152层 ImageNet错误率3.57% - 超过人类的识别率
这里 有一个在线演示深度学习的例子,可以图形化的看到完整的训练过程中Loss的变化过程,甚至图形化的方式看到每个神经元起的作用。
数学上可以证明,一个二层的神经网络可以拟合任意函数,那为什么要深度,而不是仅仅增加单层神经元数量? 因为数学上同时可以证明,如果深度不够,拟合任意函数需要的神经元太多了,所以深度是兼具拟合度和训练效率的考虑。
前提
先安装Anaconda 3.7,之所以选择3.7,是因为将来很多库已经不支持2.x的版本。Anaconda包括了很多基础库:
- NumPy 提供了大量数组和矩阵运算
- SciPy 提供了很多数值算法
- Matplotlib 提供了绘图工具
上面内置的三个库,构成了python替代matlab的基础。Matplotlib可以使用两个导入方式,通常交互环境下可以用pylab。
pylab的show()缺省是阻塞式的,调测的时候,可以先执行pylab.ion()打开交互模式,再plot/show的时候就不阻塞了,ioff()可以关闭交互模式。
Anaconda还内置了jupyter notebook,可以方便的集成代码和文档。除此以外,对于深度学习,需要安装pyTorch。
pyTorch
PyTorch 是facebook开源的深度学习框架,在学术界基本一统江湖。可以通过命令行在Anaconda下一条命令安装,如果要安装GPU加速版本,在国内安装过程因为需要下载很大的依赖包,尝尝导致安装中断,所以可以考虑使用国内Anaconda的镜像,这样设置.condarc文件
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/peterjc123/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
show_channel_urls: true
然后安装pytorch的时候,需要去掉命令行参数上的-c pytorch,这样就可以使用镜像来安装了,提高速度和安装成功率,但是很遗憾可能是因为镜像不全,如果装老版本的库就会有些问题。
PyTorch目前的GPU加速只支持CUDA,所以,最好购买计算机时选择Nvidia显卡,即使最低端的显卡,相对CPU也有数倍的速度提升,如果要训练大数据量需要足够的显存。使用keras mnist_cnn.py作为对比:3s(1080ti), 18s (MX-150), 48s(i7-6700), 76s(i7-8550u)。但要注意,每个pytorch版本兼容的gpu是不一样的,是由gpu的Compute capability version来决定的,每个显卡都有一个[对应的cc](https://en.wikipedia.org/wiki/CUDA#GPUs_supported),越新的pytorch版本兼容的最小cc也越高,最新的pytorch版本需要3.7以上的cc,可以通过torch.__config__.show()看到这个cc列表。
pyTorch的核心数据结构是Tensor,称为矢量或张量,torch.Tensor有一个重要的属性requires_grad,如果设为True,pyTorch会自动跟踪这个Tensor上的计算,在计算完成后调用.backward(), 就会在.grad属性上计算出梯度(gradients),这就是所谓的自动微分autograd,这个特性大大简化训练代码编写。
torch.nn.Module是定义模型的基类, 在这个基类上,实现一个forward方法就可以完整的定义一个深度模型,同时nn下也封装了很多预定义好的神经元。通常在写forward方法时,还需要用到大量的torch.nn.functional里的数学方法,比如max_pool2d、relu等。
很多人说到的调参实际上指的是网络结构上的参数,这些是不能通过训练得到的参数,而不是那些神经元上的可训练出的参数。
图像识别数据集
在DL历史上,MNIST是非常著名的一套手写数字识别图像集,但是它过于简单了,除此以外,还有fashion-mnist, CIFAR10等数据集,这里有一个各个数据集及相应识别率的汇总页面。
fashion-mnist,60000张10类,28*28黑白图像,相对MNIST更难一些,使用pyTorch可以方便的加载fashion-mnist,如果加载太慢,可以先从github下载下来,放到对应的目录下,一共4个文件。
import torchvision
train_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=False, download=True, transform=torchvision.transforms.ToTensor())
CIFAR10,60000张10类,32*32彩色图像, 目前最高识别率大概在96%,想更难的话,可以试试100分类的CIFAR100,识别率大概到了75%。
import torchvision
train_data = torchvision.datasets.CIFAR10(root='~/ai/cifar10', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='~/ai/cifar10', train=False, download=True, transform=torchvision.transforms.ToTensor())
有了dataset,还需要一个dataloader,dataloader可以从dataset中加载批量数据,批量(batch_size)可以让loader一次加载多个数据,这样不仅通过GPU训练更高效,loader遍历一遍数据也变快。loader也可以通过num_workers支持并行加载,但在windows下只能设置为0。
train_loader = torch.utils.data.DataLoader(train_data, batch_size=4, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=4, shuffle=True, num_workers=0)
多元分类
针对图像识别这种多元分类问题,最简单的深度网络就是SoftMax,SoftMax是在线性回归基础上发展出的分类算法,原理很简单
- 因为有多元,原有的线性回归输出层要变成N元,每个表示一个分类的置信度。
- 绝对置信度不好理解,也不容易和训练标签对应,所以将每个置信度理解为0~1的相对概率。
相应的,对应多元分类,传统线性回归的损失函数也不太合适,因为平方误差函数过于严格,而softmax输出值虽然有N个,但只有最大值有意义,通常我们使用交叉熵损失函数。
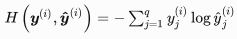
很明显,q个输出里y值只有一个为1,所以前面用y来乘,后面取log,是让对应的输出为1时, 损失函数最小,下面是一个简单的多元分类训练程序。
import time
import torch
import torchvision
train_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=False, download=True, transform=torchvision.transforms.ToTensor())
# num_workers must be 0 under windows, batch_size is key for loader performance
train_loader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=20, shuffle=True, num_workers=0)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
net = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
num_epochs = 5
print("%d: start training..." % (time.time()))
for epoch in range(num_epochs):
train_loss, train_acc, n = 0.0, 0.0, 0
for X, y in train_loader:
optimizer.zero_grad()
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
y = y.type(torch.float32)
train_loss += loss.item()
train_acc += torch.sum((torch.argmax(y_hat, dim=1).type(torch.FloatTensor) == y).detach()).float()
n += list(y.size())[0]
print('%d: epoch %d, loss %.4f, train acc %.3f' % (time.time(), epoch + 1, train_loss / n, train_acc / n))
需要注意:pytorch中softmax整合到了损失函数CrossEntropyLoss中,网络中就无需使用softmax函数了,上述代码使用CPU训练了5轮,lr可以控制收敛的速度,输出如下:
1576303662: start training...
1576303675: epoch 1, loss 0.0370, train acc 0.766
1576303689: epoch 2, loss 0.0274, train acc 0.821
1576303703: epoch 3, loss 0.0253, train acc 0.831
1576303717: epoch 4, loss 0.0243, train acc 0.837
1576303731: epoch 5, loss 0.0235, train acc 0.842
如果一直训练下去,大概到86%就最高了,这个网络只有一层输出,没有hidden layer。
FNN
FNN是前馈神经网络, 其实就是多层感知机MLP换一个名字,pyTorch来实现一个含有一个隐层的FNN
import time
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Hyper-parameters
input_size = 28 * 28
num_classes = 10
hidden_size = 500
num_epochs = 2
batch_size = 100
learning_rate = 0.001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=0)
# Fully connected neural network with one hidden layer
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('{:0.0f}: Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(time.time(), epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model, In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the {} test images: {} %'.format(total, 100 * correct / total))
这个代码和上一节有不一样的地方:
- 这里我们使用了Adam训练算法,大大提高收敛速度(即使lr很小)。
- 上述代码已经支持GPU,但我的计算机没有GPU,所以速度上比较慢。
- reshape放到了训练中,而没有放在Network里
结果和上面的单层多元分类网络差不多:
1576308516: Epoch [1/2], Step [100/600], Loss: 0.6881
1576308519: Epoch [1/2], Step [200/600], Loss: 0.4680
1576308522: Epoch [1/2], Step [300/600], Loss: 0.4607
1576308525: Epoch [1/2], Step [400/600], Loss: 0.4143
1576308527: Epoch [1/2], Step [500/600], Loss: 0.4079
1576308530: Epoch [1/2], Step [600/600], Loss: 0.3841
1576308533: Epoch [2/2], Step [100/600], Loss: 0.3728
1576308536: Epoch [2/2], Step [200/600], Loss: 0.3185
1576308539: Epoch [2/2], Step [300/600], Loss: 0.3990
1576308542: Epoch [2/2], Step [400/600], Loss: 0.4038
1576308545: Epoch [2/2], Step [500/600], Loss: 0.2982
1576308549: Epoch [2/2], Step [600/600], Loss: 0.3476
Accuracy of the network on the 10000 test images: 86.64 %
CNN
CNN就是含卷积层的神经网络,针对图像类应用,FNN网络训练效率不高,考虑下面几个特性,CNN网络做了特别设计:
- 图像的pattern通常比整个图像小。
- 图像的pattern可能出现在很多地方。
- 图像可以被缩小,并不影响识别。
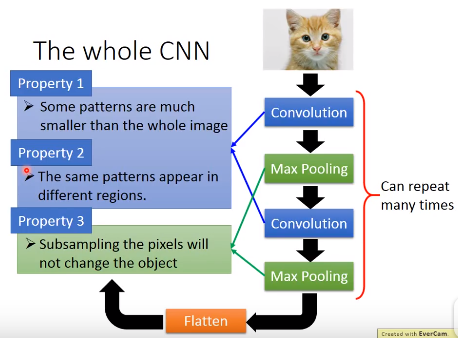
- Convolution针对上面pattern的两个特点优化
- Max pooling优化上面的缩放特性
CNN的典型应用:
- deep dream 让图片中的“特征”更明显
- deep style 让一张照片具备另一张照片的style
- 著名的alpha go,之所以用CNN,大概是因为围棋也具有上述图像的前两个特征,但除去了Max pooling。
我们使用pyTorch来实现一个CNN网络。
import time
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Hyper-parameters
num_classes = 10
hidden_size = 50
num_epochs = 2
batch_size = 100
learning_rate = 0.001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.FashionMNIST(root='~/ai/mnist', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=0)
# Convolutional neural network (two convolutional layers)
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model = ConvNet(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('{:0.0f}: Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(time.time(), epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model, In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the {} test images: {} %'.format(total, 100 * correct / total))
CNN网络的训练速度明显降低,但是识别率也相应的提升了:
1576309356: Epoch [1/2], Step [100/600], Loss: 0.4477
1576309376: Epoch [1/2], Step [200/600], Loss: 0.4096
1576309396: Epoch [1/2], Step [300/600], Loss: 0.3369
1576309416: Epoch [1/2], Step [400/600], Loss: 0.3595
1576309436: Epoch [1/2], Step [500/600], Loss: 0.4490
1576309456: Epoch [1/2], Step [600/600], Loss: 0.3161
1576309476: Epoch [2/2], Step [100/600], Loss: 0.2289
1576309496: Epoch [2/2], Step [200/600], Loss: 0.2243
1576309515: Epoch [2/2], Step [300/600], Loss: 0.2833
1576309535: Epoch [2/2], Step [400/600], Loss: 0.2114
1576309554: Epoch [2/2], Step [500/600], Loss: 0.2889
1576309574: Epoch [2/2], Step [600/600], Loss: 0.2559
Accuracy of the network on the 10000 test images: 87.89 %
ResNet
RNN 与 NLP
语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为T的文本中的词依次为w1, w2… wt,语言模型将计算该序列的概率:
P(w1, w2, … wt)
语言模型可用于提升语音识别和机器翻译的性能。例如,在语音识别中,给定一段“厨房里食油用完了”的语音,有可能会输出“厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。如果语言模型判断出前者的概率大于后者的概率,我们就可以根据相同读音的语音输出“厨房里食油用完了”的文本序列。在机器翻译中,如果对英文“you go first”逐词翻译成中文的话,可能得到“你走先”“你先走”等排列方式的文本序列。如果语言模型判断出“你先走”的概率大于其他排列方式的文本序列的概率,我们就可以把“you go first”翻译成“你先走”。
P(w1, w2, … wt)的概率随着t的增长,复杂度会指数级增长,所以通过马尔科夫假设来简化模型,即每个词只和前面的n个词相关,n作为一个模型准确率和复杂度的权衡。
GAN
GAN是近年机器学习领域最激动人心的突破,通过两个网络的”对抗”训练,来得到一个足够好的生成网络(G)和一个也足够好的识别网络(D),原始训练方法是这样的:

对抗这个词Adversarial取自最早的GAN论文,但实际上也可以把两个网络看出合作关系,互相进步。下面是使用GAN生成MNIST的例子:
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
adversarial_loss = torch.nn.BCELoss()
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
os.makedirs("~/ai/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST("~/ai/mnist",train=True,download=True,transform=transforms.Compose([transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
real_imgs = Variable(imgs.type(Tensor))
optimizer_G.zero_grad()
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
gen_imgs = generator(z)
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
optimizer_D.zero_grad()
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item()))
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
在我的机器上大概要训练8个小时,三小时之后的结果如下:

DCGAN
DCGAN在GAN的基础上将全连接网络改成卷积层,因此在图像类应用上获得了更好的训练效果,DCGAN的网络结构如下:
- 将所有的全连接层改为卷积层(生成网络和判别网络反向对称),并且不使用pooling,而是用strided convolutions。
- 在生成网络中使用反向卷积层(transposed convolutions)
- 除了生成网络的输出层和判别网络的输入串,所有层的输出都增加Batch Normalization
- 生成网络的所有层使用ReLU,除了输出层使用tanh。
- 判别网络的所有层使用Leaky-ReLU,除了输出层使用sigmoid。
代码可以使用pytorch官方sample实现,写的很好,稍加改动,缺省改为cpu,并增加时间戳的记录:
import argparse
import os
import time
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=True, help='cifar10 | lsun | mnist |imagenet | folder | lfw | fake')
parser.add_argument('--dataroot', default='datasets', help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=0)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
parser.add_argument('--cuda', action='store_true', help='enables cuda')
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
parser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')
parser.add_argument('--manualSeed', type=int, help='manual seed')
parser.add_argument('--classes', default='bedroom', help='comma separated list of classes for the lsun data set')
opt = parser.parse_args()
print(opt)
try:
os.makedirs(opt.outf)
except OSError:
pass
if opt.manualSeed is None:
opt.manualSeed = random.randint(1, 10000)
print("Random Seed: ", opt.manualSeed)
random.seed(opt.manualSeed)
torch.manual_seed(opt.manualSeed)
cudnn.benchmark = True
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
if opt.dataset in ['imagenet', 'folder', 'lfw']:
# folder dataset
dataset = dset.ImageFolder(root=opt.dataroot,
transform=transforms.Compose([
transforms.Resize(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
nc=3
elif opt.dataset == 'lsun':
classes = [ c + '_train' for c in opt.classes.split(',')]
dataset = dset.LSUN(root=opt.dataroot, classes=classes,
transform=transforms.Compose([
transforms.Resize(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
nc=3
elif opt.dataset == 'cifar10':
dataset = dset.CIFAR10(root=opt.dataroot, download=True,
transform=transforms.Compose([
transforms.Resize(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
nc=3
elif opt.dataset == 'mnist':
dataset = dset.MNIST(root=opt.dataroot, download=True,
transform=transforms.Compose([
transforms.Resize(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
]))
nc=1
elif opt.dataset == 'fake':
dataset = dset.FakeData(image_size=(3, opt.imageSize, opt.imageSize),
transform=transforms.ToTensor())
nc=3
assert dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,
shuffle=True, num_workers=int(opt.workers))
device = torch.device("cuda:0" if opt.cuda else "cpu")
ngpu = int(opt.ngpu)
nz = int(opt.nz)
ngf = int(opt.ngf)
ndf = int(opt.ndf)
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
if input.is_cuda and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output
netG = Generator(ngpu).to(device)
netG.apply(weights_init)
if opt.netG != '':
netG.load_state_dict(torch.load(opt.netG))
print(netG)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
if input.is_cuda and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output.view(-1, 1).squeeze(1)
netD = Discriminator(ngpu).to(device)
netD.apply(weights_init)
if opt.netD != '':
netD.load_state_dict(torch.load(opt.netD))
print(netD)
criterion = nn.BCELoss()
fixed_noise = torch.randn(opt.batchSize, nz, 1, 1, device=device)
real_label = 1
fake_label = 0
# setup optimizer
optimizerD = optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
starttime = time.time()
for epoch in range(opt.niter):
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
# train with real
netD.zero_grad()
real_cpu = data[0].to(device)
batch_size = real_cpu.size(0)
label = torch.full((batch_size,), real_label, device=device)
output = netD(real_cpu)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
# train with fake
noise = torch.randn(batch_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach())
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
output = netD(fake)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'
% (epoch, opt.niter, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
if i % 100 == 0:
vutils.save_image(real_cpu,
'%s/real_samples.png' % opt.outf,
normalize=True)
fake = netG(fixed_noise)
vutils.save_image(fake.detach(),
'%s/fake_samples_epoch_%03d.png' % (opt.outf, epoch),
normalize=True)
# do checkpointing
elapse = int(time.time() - starttime)
torch.save(netG.state_dict(), '%s/netG_epoch_%d_%d.pth' % (opt.outf, epoch, elapse))
torch.save(netD.state_dict(), '%s/netD_epoch_%d_%d.pth' % (opt.outf, epoch, elapse))
如果用这个来实现上面的mnist生成,在cpu上会很慢,只能把ngf和ndf改为2,这样的话,速度可以到156s/epoch,使用1650 super GPU大概比i3-9100f快20倍,8个epoch之后生成图像如下:

但是,dcgan很难训练,有时不收敛,有时又会在收敛之后忽然崩掉,判断一个dcgan网络是否稳定,需要看输出的几个重要参数:
- 训练稳定后,d_loss 最终应该稳定在 0.5~0.8左右, g_loss则大概在0.5~2左右。
- 稳定后鉴别器的正确率在80%左右。
- 稳定期之后持续训练,可能导致模型进入一个较差一些的阶段,loss震荡幅度变大,但仍然能输出不错的图像。
训练失败的最常见情况是mode collapse和convergence failure
- mode collapse 是指生成器输出的图像动态范围不足,以mnist为例,最典型的现象就是在一个batch组里输出了完全类似的图像。上面的代码中如果把nz改为1,则容易产生mode collapse问题。
- convergence failure更为常见,直观的表现就是d_loss为0,生成器只能生成一些噪声图像,鉴别器轻松的鉴别了真假图像。代码中模型capacity不够是常见导致convergence failure的原因。
文献中可以看到一些解决这些问题的几种实践方法:
- 调整lr是解决mode collapse的可行方法,lr过大容易出问题。
- Label Smoothing技术,将real image的确信度改为较低的值,比如0.9会有不错的效果。
- Multi-Scale Gradient,当训练较大的图像时,考虑使用这个技术,比nvidia的proGAN更方便。
- TTUR技术,为鉴别器和生成器使用不同的lr,比如鉴别器0.0004,生成器0.0001。
- Spectral Normalization,使用特殊形式的Normalize可以极大提高GAN的稳定性。参考这边论文。
其他的GAN
在DC基础上,有很多改进,比如WGAN,WGAN-GP,BEGAN等,Google有一篇有名的文章比较了各种GAN,最后结论是都差不多,但是Google这篇文章本身就充满争议,很多人从这篇文章的内容,看到了不同的结果。
pix2pix
pix2pix是GAN在图像转换领域一个非常成功的应用,最大的好处是使用GAN可以达到无监督学习的效果,这里的无监督不是没有素材,而是素材无需配对,比如照片到油画的转换,在训练的时候就不需要提供配对的油画和照片,只需要一堆照片和一堆油画即可。实际上不仅是图像领域,在其他领域,比如声音、文字,都可以使用GAN达到。
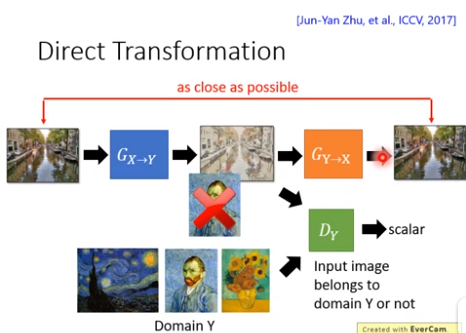
CycleGAN
这个用于将一个风格的图片转换为另一个风格,但不需要预定义的标签。
StyleGAN
StyleGAN是近年来GAN在人脸生成领域的最佳实现,StyleGAN重新设计了生成器,解决了特性重叠的问题。
BigGAN
DeepMind团队的一个令人印象深刻的GAN实现,在ImageNet图像生成上取得了碾压式的优势,但是需要巨大的网络和运算量(128块TPU训练两天),不过有报告在降低参数后,BigGAN依然有不错的效果。
参考
按顺序给出深度学习的一些好的参考资料和书籍。
- Pytorch的官方教程
- Dive into DL的pytorch版本, 这本书中英版本有明显不同,英文版本内容更丰富一些。
- 基于纯代码的Pytorch教程, 代码很整洁,值得学习。
- Kaggle 一个数据科学领域的竞赛网站,有很多非常实际的项目和很棒的实现。
- Pytorch的图片转换实现
- https://github.com/huggingface/transformers
- GAN近年的进展